
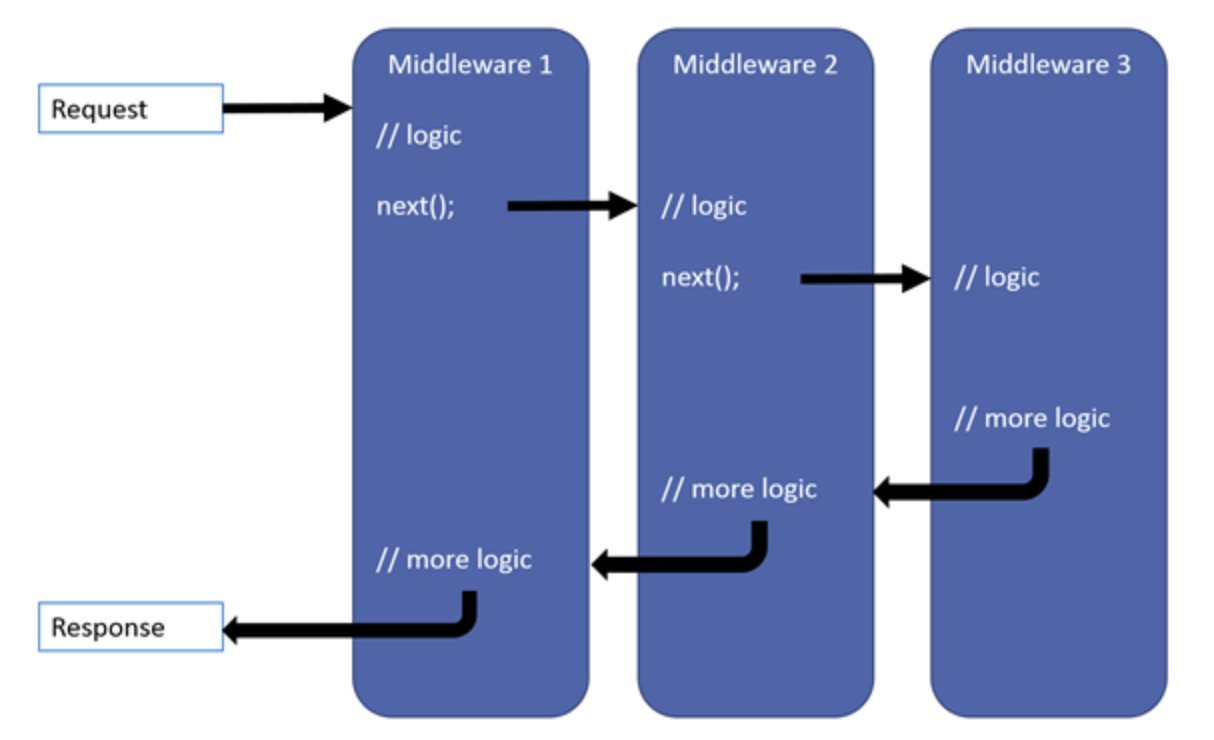
Custom Middlewares in asp.net Core
Middleware in ASP.NET Core is software that's assembled into an application pipeline to handle requests and responses. Custom middleware allows developers to insert their own logic into this pipeline to perform specific tasks, such as logging, error handling, authentication, etc.
To create a custom error handling middleware in ASP.NET Core, we'll write a middleware that catches exceptions thrown during request processing and generates a custom error response.
Here's a step-by-step guide to creating a custom error-handling middleware:
1. Create a Custom Error Handling Middleware
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Http;
using System;
using System.Threading.Tasks;public class ErrorHandlingMiddleware
{
private readonly RequestDelegate _next;public ErrorHandlingMiddleware(RequestDelegate next)
{
_next = next;
}public async Task InvokeAsync(HttpContext context)
{
try
{
// Call the next middleware in the pipeline
await _next(context);
}
catch (Exception ex)
{
// Handle the exception and generate a custom error response
await HandleExceptionAsync(context, ex);
}
}private Task HandleExceptionAsync(HttpContext context, Exception exception)
{
// Log the exception (you can use a logging framework like Serilog, NLog, etc.)// Customize the error response
context.Response.ContentType = "application/json";
context.Response.StatusCode = StatusCodes.Status500InternalServerError;
return context.Response.WriteAsync("An unexpected error occurred. Please try again later.");
}
}public static class ErrorHandlingMiddlewareExtensions
{
public static IApplicationBuilder UseErrorHandlingMiddleware(this IApplicationBuilder builder)
{
return builder.UseMiddleware<ErrorHandlingMiddleware>();
}
}
2. Register the Middleware in the Startup.cs
In the Configure method of your Startup.cs, add the following line to register the custom error handling middleware:
public void Configure(IApplicationBuilder app, IWebHostEnvironment env) {
// ... other middleware registrations app.UseErrorHandlingMiddleware(); // ... other middleware registrations
}
3. Usage
Now, any unhandled exceptions that occur during request processing will be caught by the custom error handling middleware, and an appropriate error response will be generated.
public class HomeController : Controller
{
public IActionResult Index()
{
// Simulate an exception
throw new Exception("This is a sample exception.");
}
}
In this example, when an exception is thrown in the Index action of the HomeController, the custom error handling middleware will catch it and return a customized error response to the client.
Make sure to replace the error response in the HandleExceptionAsync method with a meaningful and appropriate error message or response format based on your application's requirements.
.jpg)
.jpeg)
.jpg)
.jpg)
.jpeg)
.jpg)
.jpeg)






